
猴年马月的AGI是画大饼吗? 两位老师「吵起来了」

裁剪|冷猫
大模子的通用性和泛化性越来越遒劲了。
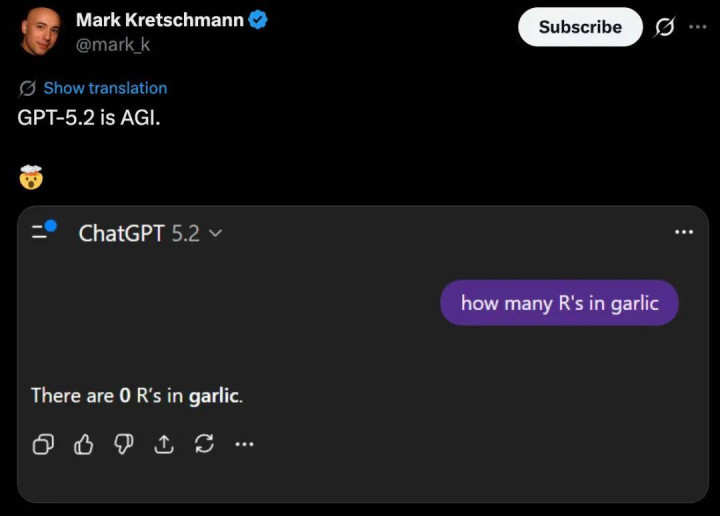
虽说一些新模子,比如说「差评如潮」的 GPT-5.2,在专科任务和智能水平如故达到了相等出色的水平,但离咱们所贯通的 AGI 依旧十分迢遥。
不外,这也评释了群众对 AGI 仍然充满讲理和信心,说不定下一款重磅的大模子就能够初步兑现 AGI 的构想呢?
但是,近期卡耐基梅隆大学老师,AI2 揣摸科学家 Tim Dettmers 发布了一篇长文博客,标题为《Why AGI Will Not Happen》,认为由于物理原因,咱们无法兑现 AGI,也无法兑现任何专诚旨的超等智能。
这篇著作实在给群众对 AGI 的讲理泼上了一盆冰水,激发了等闲哗然。

为什么 AGI 不会发生
这篇著作波及到了硬件改进、通用东说念主工智能(AGI)、超等智能、限制律例、东说念主工智能泡沫以及关连话题。

博客和谐:https://timdettmers.com/2025/12/10/why-agi-will-not-happen/
设计是物理的
许多念念考 AGI、超等智能、缩放定律以及硬件跳跃的东说念主,常常把这些见地行为抽象理念来看待,像玄学念念想实验一样加以计划。这一切都树立在对 AI 与限制化的一个根人道诬蔑之上:设计是物理的。
要兑现高效设计,你需要在两件事情之间取得均衡:其一,把全局信息移动到局部邻域;其二,将多份局部信息聚集起来,把旧信息回荡为新信息。固然局部设计的复杂性简直保持恒定 —— 更小的晶体管能够大大加快这一进程,但移动到局部设计单位的距离呈平素级增长 —— 固然也受益于更小的晶体管,但由于内存侦查模式的平素特色,改进后果很快变得次线性。
有两个重心需要记着:第一,缓存越大,速率越慢。第二,跟着晶体管尺寸束缚裁减,设计变得越来越低廉,而内存在相对意旨上却变得越来越华贵。
如今设计单位在芯片中的占比如故微不及说念,简直通盘面积都被用来作念内存。若在一块芯片上兑现 10 exaflops 的算力,但无法为它提供填塞的内存奇迹,于是这些 FLOPS 就成了 「无效算力」。
正因如斯,像 Transformer 这么的 AI 架构在试验上是物理的。咱们的架构并非不错狂妄构念念、狂妄抛出的抽象想法,而是对信息处理单位进行的物理层面的优化。
要专诚旨地处理信息,你需要作念两件事:一是设计局部关联(MLP),二是将更远方的关联聚集到局部邻域中(谨慎力机制)。这是因为,仅靠局部信息只可匡助你辞别高度摆布的内容,而聚集而已信息则能让你酿成更复杂的关联,用以对比或补充局部细节。
Transformer 架构以最简便的方式结合了局部设计与全局信息聚集,如故相等接近物理最优。
设计是物理的,这少许对生物系统相同诞生。通盘动物的设计本领都受限于其生态位中可获取的热量摄入。若大脑再大,东说念主类将无法衍生,因为无法提供填塞的能量。这使得咱们面前的智能水平成为一个由于能量舍弃而无法跨越的物理领域。
咱们接近了数字设计的领域。
线性跳跃需要指数级资源
这里同期存在两种现实:一种是物理现实,另一种是不雅念空间中的现实。
在物理现实中,如果你需要在时刻和空间上鸠合资源来产生某种结束,那么出于物流和组织的原因,想要在线性轨范上产出后果,常常就需要线性限制的资源插足。但由于物感性的舍弃,这些资源在空间或时刻上会产生竞争,使得资源的聚集速率势必越来越慢。
在不雅念空间中,也存在着类似但不那么了然于目的阵势。如果两个想法互相完全孤立,它们叠加后的后果可能比任何一个单独想法大上十倍。但如果这些想法互联系连,那么由于边际收益递减,其总体影响就会受到舍弃。如果一个想法树立在另一个之上,它所能带来的改进幅度是有限的。好多时候,只须存在依赖关系,其中一个想法就只是对另一个的细化或打磨。而这种 「精修式」 的想法,即便极富创造性,也只可带来渐进式的改进。
当一个领域填塞弘大时,即便你刻意去揣摸看起来相等不同的念念路,它们仍然与既有想法高度关连。比如,情景模子和 Transformer 看似是两种相等不同的谨慎力机制门道,但它们其实都在科罚吞并个问题。通过以这种方式考订谨慎力机制,所能获取的收益都相等有限。
这种关系在物理学中推崇得尤为昭彰。也曾,物理学的进展不错由个体完成 —— 如今基本不再可能。
不雅念空间的中枢逆境在于:如果你的想法仍然处在吞并个子领域中,那么简直不可能产生专诚旨的翻新,因为大多数东西早已被念念考过了。因此,表面物理学家试验上只剩下两条专诚旨的路可走:要么对现存念念想进行渐进式的修补与细化,其结束是影响聊胜于无;要么尝试冲破规定、提议非传统的想法,这些想法粗略很有趣有趣,但却很难对物理表面产生明确影响。
实验物理则直不雅地展示了物理层面的舍弃。为了熟谙越来越基础的物理定律和基本粒子 —— 也等于轨范模子 —— 实验的本钱正变得越来越高。轨范模子并不竣工,但咱们并不知说念该若何修补它。大型强子对撞机在更高能量下的实验,只带来了更多不笃定的结束,以及对更多表面的诡辩。尽管咱们建造了耗资数十亿好意思元、日益复杂的实验安装,但咱们依然不知说念暗能量和暗物资究竟是什么。
如果你想获取线性的改进,就必须付出指数级的资源。
GPU 不再跳跃了
我看到的最常见诬蔑之一是:东说念主们默许硬件会一直束缚跳跃。简直通盘 AI 的翻新,都由 GPU 的效用晋升所驱动。
AlexNet 之是以成为可能,是因为东说念主们开发了最早的一批 CUDA 兑现,使得卷积能够在多张 GPU 上并行设计。尔后的大多数翻新,也主要依赖于更强的 GPU 以及更多 GPU 的使用。简直通盘东说念主都不雅察到了这种模式 ——GPU 变强,AI 性能晋升 —— 于是很天然地认为 GPU 还会连接变强,并持续推动 AI 的跳跃。
试验上,GPU 如故不会再有实质性的晋升了。咱们基本如故见证了临了一代确凿紧迫的 GPU 改进。GPU 在 「性能 / 本钱」 这一方针上约莫在 2018 年傍边达到了峰值,尔后加入的只是一些很快就会被消费殆尽的一次性特色。
这些一次性特色包括:16 位精度、Tensor Core(或等价有运筹帷幄)、高带宽内存(HBM)、TMA(或等价机制)、8 位精度、4 位精度。而现在,不管是在物理层面照旧在不雅念空间中,咱们都如故走到了畸形。我在论文中如故展示过 k-bit 推理缩放定律 :在特定块大小和设计布局下,哪些数据类型是最优的。这些论断如故被硬件厂商接纳。
任何进一步的改进,都不再是「纯收益」,而只会变成权衡:要么用更低的设计效用换取更好的内存占用,要么用更高的内存占用换取更高的设计蒙胧。即便还能连接翻新 —— 而因为线性跳跃需要指数级资源 —— 这些改进也将是微不及说念的,无法带来任何专诚旨的跃迁。
固然 GPU 自身如故无法再显贵改进,但机架级(rack-level)的优化依然至关紧迫。
高效地搬运 KV cache 是面前 AI 基础设施中最紧迫的问题之一。不外,这个问题的现存科罚有运筹帷幄其实也至极径直。因为在这个问题上,基本只存在一种最优架构。兑现起来天然复杂,但更多依赖的是澄澈的念念路,以及浩荡悉力、耗时的工程责任,而不是新颖的系统设计。
不管是 OpenAI 照旧其他前沿实验室,在推理和基础设施栈上都不存在根人道的上风。唯独可能酿成上风的方式,是在机架级硬件优化或数据中心级硬件优化上后起之秀。但这些红利相同会很快耗尽 —— 也许是 2026 年,也许是 2027 年。
为什么「限制化」并不及够
我信赖缩放定律,我也信赖限制化如实能够晋升性能,像 Gemini 这么的模子昭彰是优秀的模子。
问题在于:畴前,为了获取线性改进,咱们正巧领有 GPU 指数级增长这一 「对冲身分」,它对消了限制化所需的指数级资源本钱。换句话说,以前咱们插足大致线性的本钱,就能获取线性的答复;而现在,这如故变成了指数级本钱。
它意味着一个澄澈且飞速靠近的物理极限。咱们可能只剩下一年,最多两年的限制化空间,因为再往后,改进将变得在物理上不可行。2025 年的限制化收益并不亮眼;2026 年和 2027 年的限制化,最佳能确凿顺利。
尽管本钱呈指数级增长,面前的基础设施开荒在一定进程上仍然是合理的,尤其是在推理需求束缚增长的配景下。但这依然酿成了一种相等脆弱的均衡。最大的问题在于:如果限制化带来的收益不昭彰优于揣摸或软件层面的翻新,那么硬件就会从「钞票」 变成 「欠债」。
像 MoonshotAI、Z.ai 这么的中微型玩家如故讲授,他们并不需要浩荡资源就能达到前沿性能。如果这些公司在 「超过限制化」 的方进取持续翻新,它们完全有可能作念出最佳的模子。
限制化基础设施面对的另一个紧要阻止在于:面前,大模子推理效用与弘大的用户基数高度关连,这源于汇集层面的限制效应。要兑现高效的大模子部署,需要填塞多的 GPU,才能在设计、汇集通讯以及 KV-cache 分段之间兑现存效类似。这类部署在时候上极其高效,但必须依赖弘大的用户限制才能兑现充分运用,从而具备本钱上风。这亦然为什么开源权重模子于今莫得产生东说念主们预期中的影响 —— 因为大限制部署的基础设施本钱,要求必须有填塞大的用户群体。
面前,vLLM 和 SGLang 主要在优化大限制部署,但它们并不成在小限制场景下提供相同的效用。如果有一套超过 vLLM / SGLang 的推理栈,东说念主们就不错用与 OpenAI 或 Anthropic 部署前沿模子简直疏通的效用,来部署一个约 3000 亿参数的模子。一朝较小模子变得更强(咱们如故在 GLM 4.6 上看到了这一趋势),或者 AI 应用变得愈加垂直和专用,前沿实验室的基础设施上风可能会在整宿之间隐藏。软件复杂性会飞速挥发,而开源、开权重的部署有运筹帷幄,可能在设计效用和信息处理效用上都接近物理最优。这对前沿玩家而言,是一个巨大的风险。
在限制化放缓的配景下,以下三种身分中的任何一个,都可能飞速而显贵地削弱 AI 基础设施的价值:
(1)揣摸与软件层面的翻新;
(2)遒劲的开源权重推理栈;
(3)向其他硬件平台的迁徙。
从面前趋势来看,这对前沿实验室并不是一个乐不雅的时事。
前沿 AI 旅途与理念
好意思国和中国在 AI 上采用了两种天渊之隔的旅途。好意思国顺服的是一种 「赢家通吃」 的念念路 —— 谁先构建出超等智能,谁就赢了。其中枢信念是:把模子作念到最大、最强,东说念主天然会来。
中国的理念则不同。他们认为,模子本领自身并莫得应用紧迫。确凿紧迫的是你若何使用 AI,这个模子是否实用、是否能以合理的本钱带来分娩力晋升。如果一种新有运筹帷幄比旧有运筹帷幄更高效,它就会被采纳;但为了稍许更好的后果而进行极点优化,常常并不合算。在绝大多数情况下,「填塞好」 反而能带来最大的分娩力晋升。
我认为,好意思国的这种理念是短视且问题重重的 —— 尤其是在模子本领增速放缓的情况下。比拟之下,中国的念念路愈加遥远、愈加求实。
AI 的中枢价值在于:它是否有用,是否晋升分娩力。正因如斯,它才是有意的。就像设计机和互联网一样,AI 昭彰会被用到各个边缘。这使得 AI 在全社会范围内的经济整合 对其有用性至关紧迫。
AGI 不会发生,超等智能是一种幻想
我谨慎到一个反复出现的模式:当你问硅谷的东说念主 AGI 什么时候会到来,他们总会说 「再过几年」,而且会带来巨大冲击。但当你进一步问他们 AGI 到底是什么,他们的界说里既不包含任何物理任务,也不辩论资源插足。
确凿的 AGI—— 能够作念东说念主类能作念的一切 —— 必须具备推论物理任务的本领。简而言之,AGI 必须包括能够在现实世界中完成具有经济意旨责任的实体机器东说念主或机器。
但是,尽管家用机器东说念主粗略能帮你把洗碗机里的碗拿出来,但你不会看到它们取代工场里的专用系统。工场中的专用机器东说念主效用更高、精度更强。中国如故讲授,「黑灯工场」—— 完全自动化的工场 —— 是可行的。在受控环境中,大多数机器东说念主问题其实如故被科罚。而那些尚未科罚的机器东说念主问题,常常在经济上也并不合算。比如,把 T 恤的袖子缝上去仍是一个未完全科罚的机器东说念主问题,但在大多数情境下,这件事并莫得多大的经济意旨。
机器东说念主领域的根底问题在于:学习相同顺服与讲话模子相似的缩放定律。而物理世界的数据网罗本钱极其立志,且现实世界的细节复杂到难以处理。
超等智能的根底间隙
超等智能这一见地树立在一个不实前提之上:一朝出现与东说念主类同等致使更强的智能(即 AGI),这种智能就不错自我改进,从而激发失控式的爆炸增长。我认为这是一个对通盘领域无益的、根人道不实的不雅念。
其中枢问题在于:它把智能视为一种纯抽象的东西,而不是扎根于物理现实的系统。要改进任何系统,都需要资源。即便超等智能在运用资源方面比东说念主类高效,它依然受制于我前边提到的缩放设施 —— 线性改进需要指数级资源。
因此,所谓超等智能,更像是在填补本领空缺,而不是推动本领领域外扩。填补空缺是有用的,但它不会激发失控式增长,只会带来渐进式改进。
在我看来,任缘何 「追求超等智能」为主要主义的组织,最终都会遭受巨大艰苦,并被那些确凿推动 AI 经济扩散的参与者所取代。
是的,AGI 完万能够发生
看了 Tim Dettmers 的博客心心如死灰,虽说有理有据,Dettmers 认为将 AGI 的发展树立在物理和本钱舍弃的基础上的不雅点天然是正确的,限制扩大并不是魔法,智能的进化仍需要立志的本钱。
但我总合计这个不雅点有些过甚和悲不雅。粗略 AGI 并不等同于指数加多的算力,软硬件发展粗略仍有空间。
加州大学圣地亚哥分校助理老师 Dan Fu 对于 Dettmers 的博客持反对意见,他认为 Tim Dettmers 的分析遗漏了对于面前效用以及若何充分运用系统的关节信息,现在的系统仍有巨大的发展空间,面前还不存在试验意旨上的舍弃。

这篇博客将论证现在的东说念主工智能系统在软件和硬件效用方面还有很大的晋起飞间,并抽象几条前进的说念路。并将论证咱们面前领有的东说念主工智能系统如故相等实用,即使它们不相宜每个东说念主对 AGI 的界说。

博客和谐:https://danfu.org/notes/agi/
现在的东说念主工智能系统被严重低估
Tim 的著作中一个中枢论点是:现在的 AI 系统正在接近 「数字设计的极限」。这一论点隐含了两个前提假定:其一,当下的模子(主若是 Transformer)如故极其高效;其二,GPU 的跳跃正在停滞 —— 因此,咱们不应再期待通往 AGI 的进展能够以相同的方式连接下去。
但如果你更仔细地注视试验的数据,就会发现情况并非如斯。咱们不错从老师和推理两个角度更长远地分析,这将揭示出天渊之隔的远景和潜在的前进主义。
老师:面前的老师效用远未达到上限
今天首先进模子的老师效用,其实比它 「本不错作念到的」 要低得多 —— 咱们之是以知说念这少许,是因为它致使比几年前的效用还要低。一个不雅察这一问题的方式,是看老师进程中的 MFU(Mean FLOP Utilization,平均 FLOP 运用率)。这个方针权衡的是设计效用:你到底用了 GPU 表面算力的些许。
例如来说,DeepSeek-V3 和 Llama-4 的老师在 FP8 精度下只达到了约莫 20% 的 MFU(。比拟之下,像 BLOOM 这么的开源老师模式,早在 2022 年就如故达到了 50% 的 MFU。
这种效用差距主要来自几个身分,其中一个紧迫原因是:DeepSeek-V3 和 Llama-4 都是 混杂行家(MoE)模子。MoE 层在算术强度上不如荣华 GEMM(矩阵乘)—— 它们需要更多权重加载的 I/O、更小限制的矩阵乘操作,因此更难达到高 FLOP 运用率。结束等于:相对于设计量,它们需要更多通讯。换句话说,当下的模子设计并不是为了在 GPU 上兑现最高的老师 FLOP 运用率。
此外,这些老师自身也如故是在上一代硬件上完成的。Blackwell 架构芯片的 FP8 蒙胧量是 Hopper 的 2.2 倍,况兼还赈济原生 FP4 Tensor Core。再加上像 GB200 这么的机架级有运筹帷幄,以及通过 kernel 设计来兑现设计与通讯类似,都不错缓解面前模子中的通讯瓶颈。如果咱们能兑现高效、高质料、且 MFU 很高的 FP4 老师,表面上可用的 FLOPs 将晋升到 最多 9 倍。
推理:效用问题致使更严重
在推理阶段,情况试验上更糟。最优化的推理兑现(例如 megakernel)致使不再使用 MFU 作为方针,而是关注 MBU(Maximum Bandwidth Utilization,最大带宽运用率)。
原因在于:自回首讲话模子的瓶颈常常并不在设计,而在于从 GPU 内存(HBM)把权重加载到片上存储(SRAM / 寄存器 / 张量内存)。最顶级的优化兑现,主义是尽可能荫藏这种蔓延,面前约莫能作念到~70% 的 MBU。
但如果你把视角切换回 MFU,你会发现 FLOP 运用率常常是个位数(5%)。
这并不是物理或硬件层面的根底极限。只是因为咱们最早限制化的是自回首架构(因此遇到了这些舍弃),并不虞味着它们是唯独可行、也必须用来构建通用 AI 的架构。这个领域还很新,而咱们简直不错限制通盘变量 —— 不管是软件(模子架构、kernel 设计等),照旧硬件。
前进主义:还有浩荡可挖掘的空间
一朝你确凿贯通了面前所处的位置,就会发现存几条相等澄澈的前进旅途,不错让咱们更充分地运用硬件。这些主义并不削弱,但也并非离奇乖癖 —— 事实上,每一条旅途上都如故有试验进展正在发生:
1. 老师高效的架构协同设计(co-design)
设计能更好运用硬件的机器学习架构。这方面如故有浩荡优秀责任。例如,Simran Arora 对于硬件感知架构的揣摸,以及 Songlin Yang 对于高效谨慎力机制的责任,它们标明:
Transformer 并非只须一种形态,好多变体都能保持高质料;
咱们完全不错设计出在硬件运用率上更高、且能精熟推广的架构。
2. 高质料、 高效用的 FP4 老师
如果能够在 FP4 下完成老师,咱们就能获取 2 倍的可用 FLOPs(推理侧如故启动看到 FP4 带来的加快)。面前如故有论文沿着这一主义张开探索,其中包括 Albert Tseng 和 NVIDIA 的一些相等出色的责任。
3. 推理高效的模子设计
如果咱们能设计出在推理阶段使用更多 FLOPs 的模子架构,就有可能显贵晋升硬件运用率。这里值得关注的主义包括:
Inception Labs 和 Radical Numerics 的扩散式讲话模子(diffusion LMs);
Ted Zadouri 对于 「推理感知谨慎力机制」 的揣摸。
巨大但尚未被充分运用的算力起原:踱步在天下乃至全球的手机和札记本电脑上的设计资源 —— 能否找到办法,把这些算力用于推理?
当下的 AI 老师和推理范式中,仍然存在浩荡未被运用的余量。上述每一条揣摸主义,都是在尝试填补这些闲逸,让咱们用更高的硬件运用率老师出高质料模子。
模子是硬件的滞后方针
第二个紧迫不雅点是:模子的发布与本领水平,试验上是如故启动的硬件开荒以及新硬件特色的滞后反馈。
这少许从第一性旨趣起程其实并不难贯通 —— 从一个新集群上线,到有东说念主在其上完成预老师,再到后老师结束、模子确凿能够通过 API 被使用,中间势必存在时刻滞后。
集群限制(Cluster Size)
这里我再次以 DeepSeek-V3 为例 —— 咱们相等澄澈它使用了些许硬件、老师了多永劫刻。DeepSeek-V3 的预老师发生在 2024 年末,只使用了 2048 张 H800 GPU。即便在一年之后,它依然是开源模子生态中的紧迫参与者。
而咱们也澄澈,今天正在进行的集群开荒限制要大得多:从初创公司部署的 4 万卡集群,到前沿实验室正在开荒的 10 万卡以上集群。仅从隧说念的集群限制来看,这意味着高达 50 倍的算力开荒正在发生。
新的硬件特色(New Hardware Features)
咱们今天神用的大多数模子,在某种意旨上也都是老模子,因为它们是在上一代硬件上老师的。而新一代硬件带来了新的特色,模子需要围绕这些特色进行(从头)设计。
FP4 老师,如果可行,是一个相等明确的突破主义;
GB200 的机架级通讯域(NVL72 通过高速 NVLink 将 72 张 GPU 勾通在一皆)亦然另一个极其澄澈的突破点 —— 它们既能缓解第少许中提到的低 FLOP 运用率问题,也为探索全新的模子设计提供了杠杆。
咱们面前仍然处在 Blackwell 硬件周期的相等早期阶段。就在最近发布的 GPT-5.2,是最早一批使用 GB200 老师的模子之一(尽管它似乎也同期使用了 H100 和 H200)。
此外,还有一些不那么显眼、但相同关节的硬件改进。一个例子是:在 B200 上,谨慎力设计是受限的,但瓶颈并不在 Tensor Core,而是在指数运算上。原因其实很简便 ——Tensor Core 在代际升级中快了 2.2 倍,但超过函数单位(transcendental units)的数目或速率却莫得同比增长。好讯息是,这类问题相对容易科罚。B300 将超过函数单位数目翻倍,这在一定进程上不错缓解这一瓶颈。
这些硬件改进天然需要工程插足,但再次强调 —— 这并不是什么火箭科学。这里存在浩荡顺手可取的低落果实。
前进旅途
在贯通了上述配景之后,咱们不错给出一些具体且现实的前进主义,来进一步晋升驱动顶级模子的有用算力:
1. 「加快恭候」
在很猛进程上,咱们面前仍然是在不雅察那些基于上一代集群预老师的模子推崇。而一些团队如故完成或正在完成新一代超大限制集群的开荒。这很可能只是一个恭候模子发布的阶段性问题。
2. 面向硬件的专项优化
还有浩荡责任不错围绕新一代硬件特色张开:例如咱们前边提到的 FP4;再如围绕竣工的机架级通讯域来设计模子;或者针对 B200 / B300 上指数运算瓶颈的特色,对谨慎力机制进行适配和重构。
3. 新硬件与新的算力起原
临了,还有浩荡新硬件平台正在炫耀,以及配套的软件栈,使它们能够被 AI 所使用。如今的新硬件平台简直层出叠现,许多都专注于推理场景,这里我不点名任何具体有运筹帷幄。但只须其中任何一个确凿产生紧要影响,通盘时事都会被透彻改写。
距离有用的 AGI 到底还有多远?
临了一个不雅点,关注点如故不再主若是系统层面或算力层面的 AI,而是 AGI 究竟意味着什么,以及要产生确凿、可不雅的影响究竟需要什么。
贯通这一部分的一个角度是:即便世界上通盘系统层面和效用层面的跳跃都俄顷停滞,那么距离 「有用的、类似 AGI 的本领」 确凿落地,咱们还差多远?
如果你把 AGI 贯通为一种 「魔法棒」—— 不错挥一挥就完成地球上任何一个东说念主能作念的任何事情 —— 那昭彰咱们还远远莫得到达阿谁阶段。
但如果换一种更求实的界说:一套在某些任务上比大多数东说念主作念得更好、并能产生巨大经济影响的通用器具体系,那咱们粗略并莫得联想中那么迢遥。
在这里,我认为有必要回头望望只是两三年前的情景。不管是开源模子照旧前沿模子,今天所能作念到的许多事情,在其时简直都像是魔法。就我个东说念主而言,像 Claude Code、Cursor Composer 这么的器具,如故越过了一个关节阈值 —— 我写的大多数代码,如故是由模子生成的(这篇博客自身我倒照旧用 「传统方式」 写的)。
在 GPU 内核工程这个领域,大模子带来的影响,有几点尤其让我感到诧异:
在东说念主类参与的前提下,这些模子如故相等擅长编写 GPU 内核代码。它们还没到完全零样本(zero-shot)的进程,但只须提供填塞的荆棘文和诱惑,就不错兑现跨越栈中多个部分的复杂功能。这自身等于一种极具挑战性、且在现实中相等稀缺的工程本领,即便对资深武艺员来说亦然如斯。
这些模子在编写器具链和构建可视化方面推崇极佳,匡助咱们贯通下一步性能优化该往那处鼓舞 —— 从日记系统,到责任负载模拟,再到性能瓶颈的可视化分析。
即便只在现存本领基础上小幅前进,也不难联想模子能摄取更大比例的时候栈,尤其是在东说念主类参与的限制模式下。事实上,这一代模子如故好用得离谱了。
即使假定咱们无法获取任何更高效的新算法或新硬件,咱们可能如故掌执了一种方法,不错构建在特定领域中科罚或加快 95% 问题的通用 AI 智能体或模子。
至少不错校服的是,咱们如故领有了一整套器具,只须互助合适的数据网罗方式(例如 RLHF、构建强化学习环境)以及领域行家常识,就能被迁徙到各式不同问题中。编程之是以首先被攻克,一个很天然的原因是:简直通盘 AI 揣摸者都会写代码,而它自身又具有极高的经济价值。
天然,这里也恰是 AI 揣摸的 「主战场」。在上述管制条目下,咱们仍然不错设计多种鼓舞 「有用 AI 器具」 的方式:
1. 新的后老师范式(Post-training formulas)
今天咱们所说的后老师,既新也旧 —— 新在具体实践方式(大限制 RLHF、构建环境测试模子等),旧在其中枢念念想自身。市面上之是以会出现诸如 Tinker 以及各式微调 API 平台,并非偶而。
2. 更好的样本效用(Sample complexity)
构建在更少数据、更少样本下也能学得更好的老师系统,或者设计更优的数据筛选算法,以晋升样本效用。总体而言,「以数据为中心的 AI(data-centric AI)」这一揣摸群体,正持续在改善这一时事。
3. 传统意旨上的 「硬功夫」和领域教训
临了,即便咱们自缚双手,假定模子本领完全不再晋升 —— 仍然有浩荡应用场景和垂直领域,今天的 AI 模子就如故不错产生巨大影响。即使模子质料被冻结,系统层面的效用改进,也足以让许多高影响力应用确凿落地。
咱们仍然处在贯通和构建这项新时候的相等早期阶段。从若何将其用于确凿世界的影响,到若何让它更好地为东说念主类奇迹,还有浩荡责任要作念。这是一个令东说念主沸腾的期间。
论断:通往 AGI 的多条说念路
这篇博客的中枢不雅点是:面前的 AI 系统仍然存在巨大的晋起飞间,而通往更强 AI 的说念路也远不啻一条。只须仔细不雅察,你会发现通向至少一个数目级(10×)算力晋升的具体旅途和揣摸议程。
回到这篇著作领先的动机:我相等赏玩 Tim 那篇博客的少许在于,它怡悦直面从今天走向畴昔所必须跨越的具体抵制。咱们不错共同设计更好地运用现存和畴昔硬件的新模子,也不错沿着多条旅途鼓舞,构建更强、更有用的模子。而将潜在路障如斯澄澈地摊开计划,自身就为 「接下来该作念什么、若何去作念」 提供了一张门道图。
三点总结
1. 面前 AI 系统对硬件的运用率极低。通过更好的模子–硬件协同设计,咱们不错兑现更高的 FLOP 运用率,获取更多 「有用的 FLOPs」。
2. 面前模子是硬件开荒的滞后方针 —— 不管是 GPU 的实够数目,照旧新硬件特色的运用进程。
3. 即便不依赖系统层面的进一步改进,咱们仍然不错通过更好的算法,让今天的模子在更等闲的领域中变得极其有用。事实上,今天的模子如故相等有价值了。
天然,前线一定会有时候挑战。但我个东说念主相等接待这些挑战,也期待看到揣摸者和工程师们接下来会给出奈何的谜底。从事 AI 与系统揣摸,从未有过比现在更好的期间,也从未如斯令东说念主沸腾。
竣工内容,请参阅原始博客。