
OpenAI最强编程模子溃逃! 不敌谷歌Gemini, 罅隙审查差太多

全球好,我是小圆!AI编程器具之间的“圣人打架”,老是能诱骗不少开导者和科技谨慎者的视力。最近,这场竞赛又添了新剧情:OpenAI高调发布了其最新的编程专用模子GPT-5.2-Codex,并称之为“迄今为止最强的编程模子”。
但没过多久,就有测试炫耀,它在与老敌手谷歌的Gemini模子同台竞技时,尤其是在查找代码罅隙的任务中,果然透露落了下风。这场堪称“最强”的发布,似乎开场就遭受了一个窘态的对比。这到底是若何回事?让咱们一齐来望望。

功能强化,但“最强”名称遭挑战
就在前几天,OpenAI负责推出了GPT-5.2-Codex。这个模子基于GPT-5.2更正而来,重心强化了与编程策划的各项才气。
把柄官方先容,它在处理复杂的遥远任务、进行大范围代码改革、相宜Windows环境以及积聚安全防御等方面,齐有了成心的优化。纯粹来说,OpenAI但愿它不仅能写代码,更能像一个果然的软件工程师或安全群众那样,去知道、导航以致重构一个大型代码库。

新功能听起来很诱东谈主,比如它压缩和知道长段信息的才气更强了,解读工夫图表和截图也更精确,在末端敕令行操作上也比前代更闇练。OpenAI也公布了一些基准测试得益,炫耀它在某些轨范化的编程问题责罚测试上,分数如实比之前的版块要高一些。
可是,就在官方宣传其“最强”实力的时分,一场来自社区的、不那么“轨范”的对比测试,却给出了不同的故事。


罅隙审查效力与恶果双输
模子发布后,很快就有工夫谨慎者迫不足待地将它与谷歌刚刚推出的Gemini 3 Flash模子放在一齐“跑了个分”。他们打算了一个十分面临履行的测试:让两个AI同期审查50个文献中的代码,看谁能更快、更准地找出其中的安全罅隙。
适度有点出东谈主预思。谷歌的Gemini 3 Flash仅用了1分2秒就完成了扫描,并指出了5个潜在问题。而OpenAI的GPT-5.2-Codex花了快要5分钟,耗时是对方的四倍多,最终只找到了2个问题,况兼这两个问题齐也曾被Gemini发现了。

在编程和安全范围,速率和准确性即是生命线,这场凯旋对比让“最强”名称显得有些窘态。这个测试天然可能仅仅个例,但它指向了一个重要问题:官方公布的基准测试得分,有时分和责罚真实寰球复杂问题的才气并不可十足划等号。
罅隙审查需要模子具备深度的逻辑推理、模式识别和对代码意图的精确把抓,这场“翻车”似乎阐明,新模子在处理这类详细性实战任务时,可能还存在短板。那么,它的其他阐发究竟如何呢?

性能升迁未达预期?
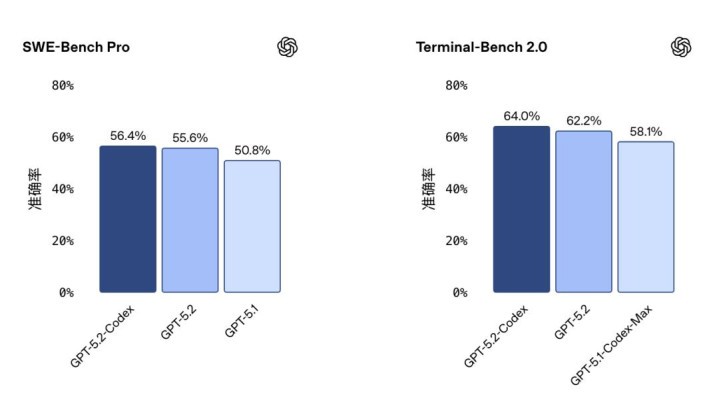
要是咱们谢额外去看OpenAI我方公布的基准测试阐明,会发现情况有些复杂。一方面,在像SWE-Bench Pro(一个评估模子建立真实寰球GitHub问题才气的测试)上,GPT-5.2-Codex的得分比前代有微幅升迁,达到了56.4%。在末端任务测试上,逾越则比拟透露。
这些数据阐明,它在某些维度的才气如实在迭代逾越。但另一方面,也有提神的社区成员指出,此次性能升迁的幅度可能莫得全球期待的那么大。
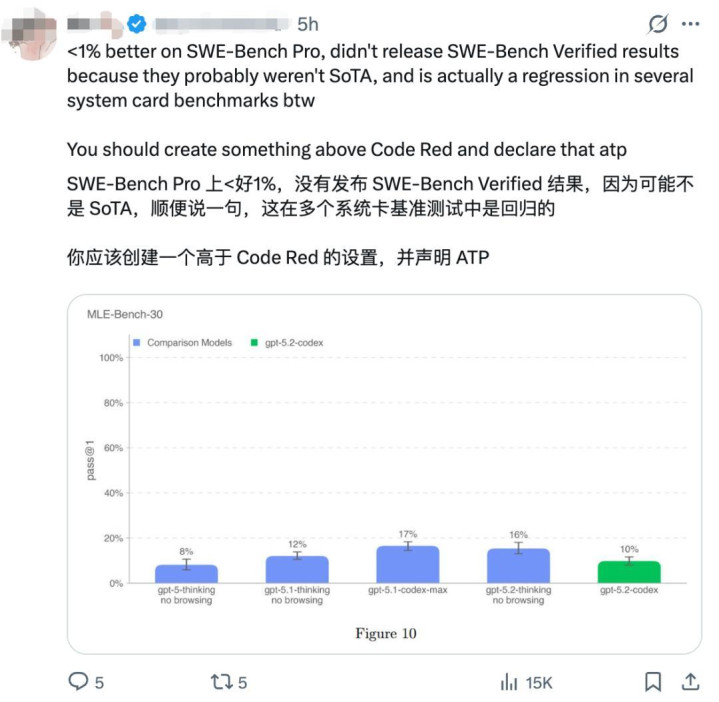
有音信称,其在SWE-Bench Pro上的升迁还不到1个百分点,而且OpenAI此次莫得发布另一项更严格的“已考据”测试适度。这不由得让东谈主臆度,这个“最强”模子约略并莫得在工夫极限上齐备紧要冲突,以致可能在某些系统测试中出现了波动。
官方展示的逾越和社区实战测试的繁重,共同勾画出一个更立体的画像:这是一个有针对性更正的迭代版块,但并非在通盘场景下齐能碾压敌手。


OpenAI与谷歌在AI编程赛谈上的竞争,也曾插足了火器再见的深水区。GPT-5.2-Codex的发布,体现了OpenAI在深刻模子专科工程才气方面的奋发,其长高下文处理、末端操作等升级对开导者有履行价值。
关于开导者和企业用户来说,这场“最强”之争的插曲无意是赖事。它阐明莫得一家厂商能把持通盘上风,竞争正在迫使它们束缚表露短板、优化长板。
改日,罗致AI编程助手可能不再仅仅看品牌,而是需要把柄具体的任务类型——是平方代码补全、大型神志重构,照旧至关伏击的安全审计——来匹合营适的器具。这场刚刚初始的较量,适度将凯旋决定咱们改日编写和看护代码的格局。
下一篇:没有了